Data Frame Forwarding: Master Efficient Network Switching Techniques (Updated 2025)
")
Ethernet switching is a cornerstone of modern networking, enabling efficient data transfer in local area networks (LANs). For CCNA and CCNP students, understanding switching methods like store-and-forward and cut-through is critical for designing and troubleshooting networks.
This article explores the evolution from Ethernet bridges to advanced LAN switches, focusing on frame forwarding techniques, their characteristics, and their applications in Cisco environments. Whether you’re preparing for certification or optimizing a network, mastering these concepts is essential.
Evolution from Ethernet Bridges to LAN Switches
As networks grew, Ethernet bridges were used to segment collision domains, reducing network congestion. However, bridges had limitations, such as software-based frame forwarding and limited port scalability. The advent of application-specific integrated circuits (ASICs) enabled LAN switches, like Cisco Catalyst series, to replace bridges. Modern switches use hardware-based frame forwarding, significantly reducing packet-handling time and supporting high port densities without performance degradation. For example, a Cisco Catalyst 9200 switch can handle thousands of frames per second using ASICs, making it ideal for enterprise LANs.
Store-and-Forward Switching
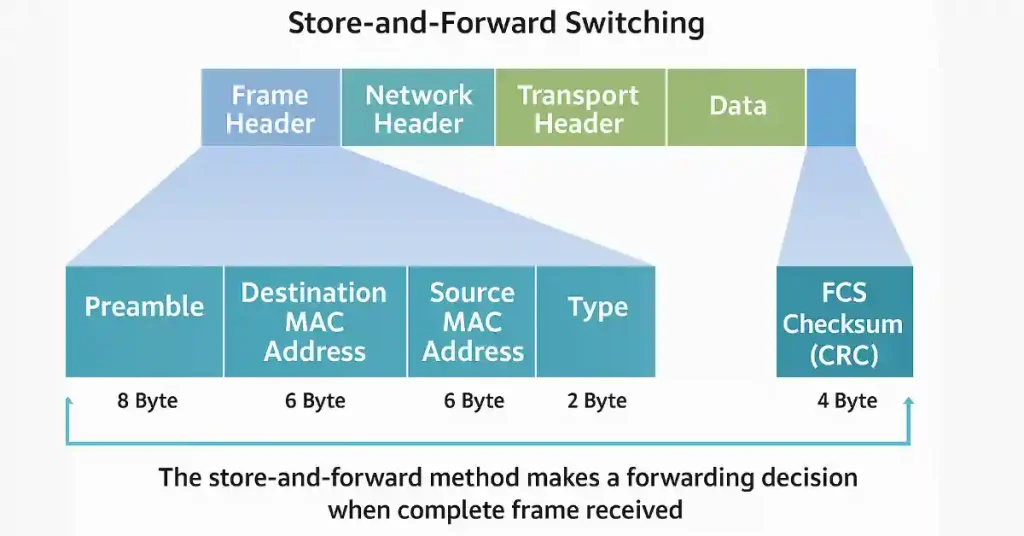
Store-and-forward switching is a robust method where the switch receives the entire frame before making a frame forwarding decision. This method is widely used in Cisco switches, such as the Catalyst 9300 series, due to its reliability.
How It Works
- The switch receives the complete frame on the ingress port.
- It performs a cyclic redundancy check (CRC) using the frame-check-sequence (FCS) field to detect errors.
- If the CRC is valid, the switch looks up the destination MAC address in its MAC address table to determine the egress port.
- The frame is forwarded to the correct port; otherwise, it’s dropped.
Key Characteristics
- Error Checking: The switch calculates the FCS and compares it with the frame’s FCS to ensure no physical or data-link layer errors. This prevents corrupted frames from propagating.
- Automatic Buffering: If ingress and egress ports operate at different speeds (e.g., Fast Ethernet to Gigabit Ethernet), the switch buffers the frame, ensuring smooth transmission.
Cisco Example
In a Cisco Catalyst switch, store-and-forward is the default mode. For instance, when a frame arrives at a 100 Mbps port and needs to exit a 1 Gbps port, the switch buffers the frame, performs CRC, and forwards it. You can verify this behavior using the command:
show interfaces <interface> | include CRC
Comparison Table
| Feature | Store-and-Forward | Cut-Through |
|---|---|---|
| Error Checking | Yes (CRC) | No |
| Latency | Higher | Lower |
| Buffering | Automatic | None |
| Cisco Switch Support | Default (e.g., Catalyst 9300) | Optional (e.g., Catalyst 9500) |
Cut-Through Switching
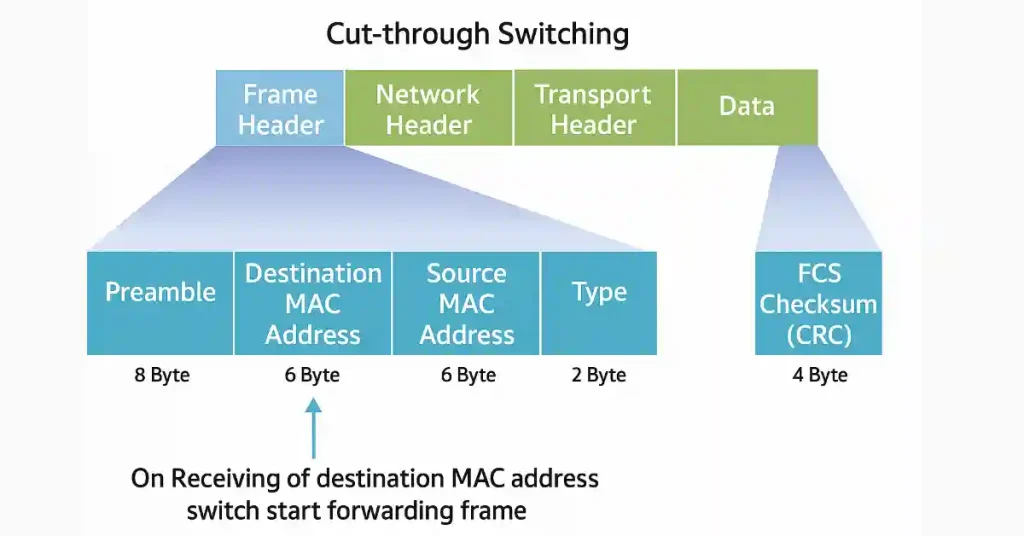
Cut-through switching prioritizes speed by frame forwarding as soon as the destination MAC address is read, typically after the first 6 bytes of the frame. This method is used in high-performance environments, such as Cisco Catalyst 9500 switches, for low-latency applications.
How It Works
- The switch reads the destination MAC address (6 bytes) from the frame header.
- It looks up the MAC address table to determine the egress port.
- The frame is forwarded immediately, without waiting for the entire frame.
Key Characteristics
- Rapid Frame Forwarding: Minimizes latency by forwarding frames early, ideal for high-performance computing (HPC) environments requiring latencies below 10 microseconds.
- No Error Checking: Invalid frames are forwarded, potentially reducing bandwidth if errors are frequent.
Fragment-Free Switching
Fragment-free switching, a variant of cut-through, waits for the first 64 bytes (collision window) to ensure no frame fragments before forwarding. This balances low latency with basic error checking, making it suitable for environments with moderate error rates.
Cisco Example
Cisco switches like the Catalyst 9500 support cut-through switching for specific ports. You can configure it using:
interface <interface>
switchport mode cut-through
Verify with:
show interfaces <interface> switchport
Rapid Frame Forwarding
A cut-through switch moves forward immediately when it finds the frame’s destination MAC address in its MAC address table. Unlike the store-and-forward method, the switch doesn’t need to wait for the complete frame.
Because of ASICs and MAC controllers, a switch using the cut-through method can quickly decide. The cut-through method needs to check a larger part of a frame’s headers for more filtering purposes. For example, the switch can check the source MAC address, destination MAC, and the Ether Type fields, which total 14 bytes, and check an extra 40 bytes to carry out more difficult functions in Layers 3 and 4.
Practical Applications
Understanding switching methods is crucial for network design and troubleshooting. Here’s how store-and-forward and cut-through switching apply in real-world scenarios:
Use Cases
- Store-and-Forward: Ideal for enterprise networks with mixed-speed interfaces (e.g., 100 Mbps to 10 Gbps) or environments requiring high reliability, such as data centers. Used in Cisco Catalyst 9300 switches for VLAN traffic.
- Cut-Through: Preferred in low-latency environments like financial trading systems or HPC clusters. Cisco Catalyst 9500 switches support cut-through for specific ports.
- Fragment-Free: Used in networks with moderate error rates, balancing latency and reliability.
Performance Considerations
- Latency: Cut-through offers lower latency (e.g., 5–10 µs) compared to store-and-forward (50–100 µs).
- Throughput: Store-and-forward ensures error-free transmission, maximizing throughput in error-prone networks.
- Cisco QoS: Quality of Service (QoS) configurations can prioritize cut-through for time-sensitive traffic.
Configuration Example
To enable cut-through on a Cisco Catalyst switch:
configure terminal
interface GigabitEthernet0/1
switchport mode cut-through
end
Verify with:
show running-config interface GigabitEthernet0/1
Best Practices for Switch Configuration
- Use VLANs to segment traffic.
- Implement QoS for priority data.
- Troubleshoot with show mac address-table and show interfaces.
Conclusion
Ethernet switching is a fundamental concept for CCNA and CCNP students, enabling efficient and scalable LANs. Store-and-forward switching ensures reliability through error checking and buffering, while cut-through and fragment-free switching prioritize speed for low-latency applications. By mastering these methods and their Cisco implementations, you’ll be better prepared for certification exams and real-world network challenges. Explore Cisco’s official documentation or practice in a lab to deepen your understanding.
Frequently Asked Questions
-
Store-and-forward switching waits for the entire frame, performs error checking (CRC), and buffers if needed, ensuring reliability. Cut-through switching forwards frames after reading the destination MAC address, prioritizing low latency but not checking for errors.